AML Logo Design Project
Non-designer designs the design of laboratory’s symbol, interestingly.
- 사람, 고양이, 자동차 등의 생명체 및 물체는 전반적으로 좌우 대칭합니다. 만약 최신 유행하는 물방울 모양의 앞머리 스타일을 가진 남자를 분석한다면 쉽지 않겠지만 3D이미지를 생성하는 데에 있어서 이러한 예외적인 상황은 유의미하지 않습니다.
- 좌우 대칭이 깨진 경우도 depth 관련하여 confidence matrix를 관리하여 모델을 개선합니다(후술 예정).
❑ 기존 모델의 경우 3D 이미지를 트레이닝 하고 반환을 하는 데에 있어서 input 데이터에 많은 annotation이 필요했습니다. 3D 이미지는 크게 가로, 세로, RGB(3), depth, albedo 등 깊이감과 빛과 관련된 요소를 예측해야하는 데 supervised learning시 많은 annotation, label 이 필요한 바 시간, 비용적 자원을 많이 소요합니다.

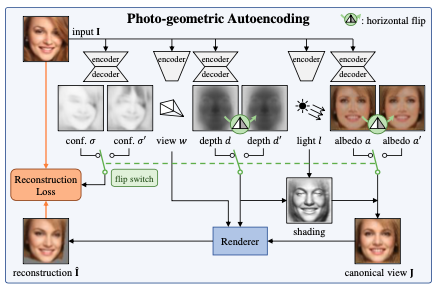
Photo-geometric autoencoding을 직역하면 사진-기하학 자동인코더입니다. confidence matrix, depth, albedo 인자에는 encode-decode과정이, light, view 인자에는 encode만이 이루어집니다. 이 모델의 핵심인 ‘대칭성◭ ‘은 flip switch에서 확인 가능합니다.
Concept is “정방향 이미지 + (대칭성 가정에 의한)미러 이미지 활용 → 3D 모델링 개선”
이미지 I는 카메라가 3D 물체를 바라보는 시점의 데이터입니다. I는 viewpoint에 따라 P로 이루어져 있습니다. P는 x, y, z 3개 차원의 데이터입니다. p(pixel)는 K행렬과 P 값의 곱으로 맵핑됩니다. 여기서 u, v는 canonical view의 값입니다.
\[P=\left(P_{x}, P_{y}, P_{z}\right) \in \mathbb{R}^{3}\](Eq5)
$p \propto K P, K= \begin{bmatrix} f & 0 & c_{u}\cr 0 & f & c_{v}\cr 0 & 0 & 1 \end{bmatrix} , \begin{cases} c_{u}=\frac{W-1}{2}\cr c_{v}=\frac{H-1}{2}\cr f=\frac{W-1}{2 \tan \frac{\theta_{\mathrm{FOV}}}{2}} \end{cases} $
where $p=(u, v, 1)$
canonical view 에서 다른 각도의 view 로 이미지를 변환하기 위해서는 u, v값이 u’, v’값으로 치환되어야 합니다. 이를 위해 Warping Function이 적용됩니다.
Warping Function은 Canonical View에서 다른 View로 이미지를 변환 시킵니다. u, v는 Canonical View일 때의 인자,u’, v’ 는 Warping Function 적용이후 다른 View일 때의 인자입니다.
Warping Function $\eta_{d, w}:(u, v) \mapsto\left(u^{\prime}, v^{\prime}\right)$ given by $p^{\prime} \propto K\left(d_{u v} \cdot R K^{-1} p+T\right)$ where $p^{\prime}=\left(u^{\prime}, v^{\prime}, 1\right)$
$\mathcal{L}(\hat{I}, I, \sigma) = \frac{1}{|\Omega|} \sum_{u v \in \Omega} \ln \frac{1}{\sqrt{2} \sigma_{u v}} \operatorname{exp} \frac{\sqrt{2} \ell_{1, u v}}{\sigma_{u v}}$
위의 L1 loss function은 작은 기하학적 결함에 의해 희미한(blurry) 이미지 결합을 만들 가능성이 있습니다. 이를 해결하고자 따라 ‘e’(perceptual loss function(off-the-shelf image encoder))을 적용합니다.
$e^{(k)}(\mathbf{I}) \in \mathbb{R}^{C_{k} \times W_{k} \times H_{k}}$
$\Omega_k= \lbrace0, … \ldots, W_k-1\rbrace \times \lbrace0, … \ldots, H_k-1\rbrace$
$\ell_{u v}^{(k)}=\lvert e_{u v}^{(k)}(\hat{\mathbf{I}})-e_{u v}^{(k)}(\mathbf{I})\rvert$

conf σ 가 있느냐 없느냐에 따라 퍼포먼스가 확연히 차이가 남
앞서 말한 모델의 큰 특징 2가지를 먼저 열거하고 설명하겠습니다.
대칭성이라는 Ground Premise 를 모델이 상정은 하였으나 현실적으로 앞으로 활용될 모든 이미지가 그 가정을 따르지는 않습니다. 이에 따라 좌우대칭이 아니거나, 노이즈가 있는 데이터(=Perturbed Data)를 더불어 트레이닝 시키고 Confidence Map을 관리하며 모델의 퍼포먼스를 개선하였습니다.
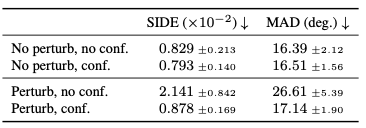
이는 수치로도 알 수 있습니다(SIDE, MAD(작을수록 우월)).
당연히 Perturb Data가 No-Perturb보다 퍼포먼스가 떨어지는 것은 사실이나 주목 해야할 것은 Confidence Map 관리를 통하여 Perturb Data의 경우 정확도가 크게 향상 (SIDE: 2.141 → 0.878, MAD: 26.61 → 17.14) 합니다.
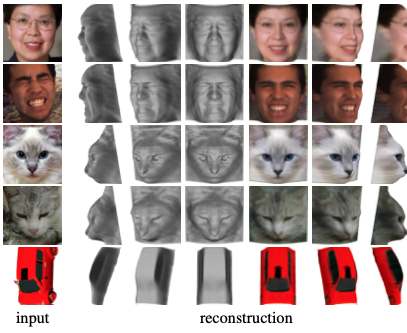
CelebA, 3DFAW에서 인물 얼굴을, ShapeNet에서 고양이와 자동차 이미지를 활용하여 해당 모델에 트레이닝 시켜본 결과입니다. 현실과 상당히 가깝게 3D이미지를 deformation하는 것을 확인할 수 있습니다.

나아가 고전명화, 만화 이미지를 넣어도 그럴 싸한 결과를 냅니다. 루브르에 직접 가도 못 볼 모나리자의 Rear Face를 뉴럴네트워크가 생산해낼지는 상상도 못했습니다⚡

모델은 Canonical View를 Autoencoder를 통해 생성합니다. 이에 따라 이미지의 수직센터라인을 생성하는 것은 지당히 쉽습니다(symmetry plane). kingsman
또한 비대칭 이미지, 조명이 과장되었거나 불안정한 이미지에도 좋은 퍼포먼스를 냅니다. Confidence Map의 관리를 통해 Depth 트레이닝시에 비대칭인 부분에 대해서는 Confidence를 극히 낮추어, 비대칭성에 의한 퍼포먼스 저하를 방지합니다.

3D estimation의 State-of-the-Art 알고리즘과 해당 모델을 비교한 결과입니다. 논문 저자는 본 모델은 single view 이미지를 활용해 unsupervised learning으로(=즉 간편한 과정으로) 비슷한 퍼포먼스를 내었다고 재차 강조합니다. Numerical Comparison은 없습니다. 저자가 SOTA 알고리즘의 코드를 확보하지 못해서라고 합니다.

밝음의 정도 편차가 극심하거나(a) 표면의 모양이 복잡하거나(b), 자세, 각도가 극단적(c)인 경우 모델의 퍼포먼스가 좋지 않습니다. 이는 여러 극단적은 요소로 인해 정면 이미지가 정확히 반환되지 않았기 때문입니다. 대칭성과 같은 정면이미지에 대한 premise, constraint 를 더 추가한다면 개선의 여지가 있다고 합니다.
❑ 단차원 이미지로 3차원 이미지를 생산해내는 것(큰 노력 없이 (a.k.a. Unsupervised Learning))은 이미지 분야에서 하는 디자이너들의 고된 작업을 덜어주어 Human Creativity을 발휘할 다른 일에 집중케하는 데에 의의가 있다고 사료됩니다.
❑ 활용될만한 분야가 상당히 많은 방법론입니다. 바로 떠오르는 분야는 아래와 같습니다.
결국 “symmetric” 가정이 이를 가능케한 것인데, 이 가정이 깨진 케이스는 어떻게 할것이냐라는 물음이 따라다닙니다. 물방을 헤어스타일을 한 남성의 이마에도 정확한 그림자를 부여하고자 하는 수요는 많지는 않겠지만 존재할 수도 있는 것입니다. 개선된 방법론이 나오지 않을까 생각합니다.
끝.
Non-designer designs the design of laboratory’s symbol, interestingly.
How to Use GSDS GPU Server
Fairness Definitions Explained
Fairness ML is the remedy for human’s cognition toward AI
과학자의 자세
미션: Shell 운용하는와중에 구글 검색하느라 시간 버리지 않기
Life Advice by Tim Minchin / 이번생을 조금이나마 의미있게 살고자
TensorflowLite & Coral Arsenal
Hivemapper,a decentralized mapping network that enables monitoring and autonomous navigation without the need for expensive sensors, aircraft, or satellites.
AMP Robotics, AI Robotics Company
자율주행 자동차 스타트업 오로라
Here I explore Aurora, tech company founded by Chris Urmson
Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks
미국의 AI 스타트업 50곳
2014 mid 맥북프로에 리눅스 얹기
Sparse Encoder, one of the best functioning AutoEncoder
Basic Concept of NN by formulas
싱글뷰 이미지로 다차원뷰를 가지는 3D 객체를 생성하는 모델
고통의 코랄 셋업(맥북)
HTML 무기고(GFM방식)